
The music of the '00s -- why did we like what we like?
The goal of this post is to jumpstart an awesome exploration of music and data from the ’00s. This post is meant to serve as a companion writeup to the ‘Are You Entertained?’ podcast, in which we continue to address an omnipresent question in the industry- why do we like what we like?
STEP 1: Exploring the raw data…
There are a total of 83 columns with 76 of those containing rank values per week (76 weeks). I looked over the first ten rows of data. I observed that the values in the ‘weeks’ columns are relative ranks of tracks on the Billboard 100 chart for that week. The current dataset uses asterisks in place of missing values. I will need to replace asterisks with NaN. Also, it seems that the final columns (e.g., 68+ weeks) don’t have any data (seems like all asterisks). I plan to look into this further somehow (like find total NA in column or something). Perhaps I can drop some columns if no values exist in them.
The strings in ‘artist.inverted’ column are not all formatted the same way. Not sure if that is going to matter during the data analysis (I suspect not, but duly noted). The column names do not contain unnecessary spaces nor are they unnecessarily long (in my opinion). However, I will rename the ‘artist.inverted’ column because that label is inaccurate (names for groups of artists, such as a band, are not inverted). I also don’t like the dots in the column names. The dots in the column names might cause confusion while coding. I will need to reformat the values in the following columns: ‘time’, ‘date.entered’, ‘date.peaked’. After reviewing the values in the ‘date.entered’ and ‘date.peaked’ columns, I think I am going to have to create another column using those two columns that will yield more informative date information for each week a track is on the billboard chart.
I also took a look at the data types of each column, and observed that I would have to change them for several columns. I also observed that some of the genres seem to overlap (e.g., Rock vs Rock’n’roll). Also, some artists have seemingly wrong genres listed (e.g., rock for a pop artist). However, this is not something I can fix since that’s based on opinion (I think), and so I will just duly note this observation.

STEP 2: Cleaning up the data…

STEP 3: Visualizing the data…
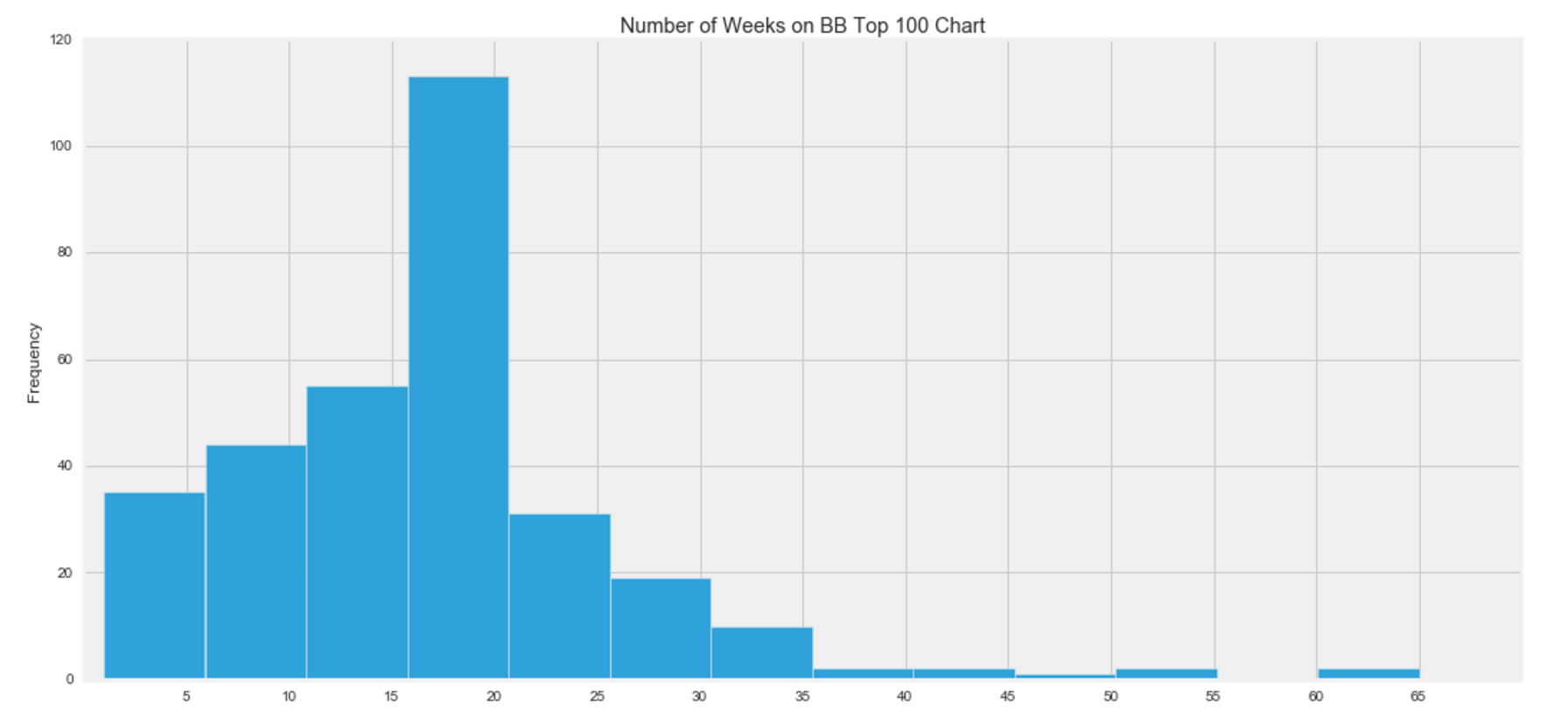
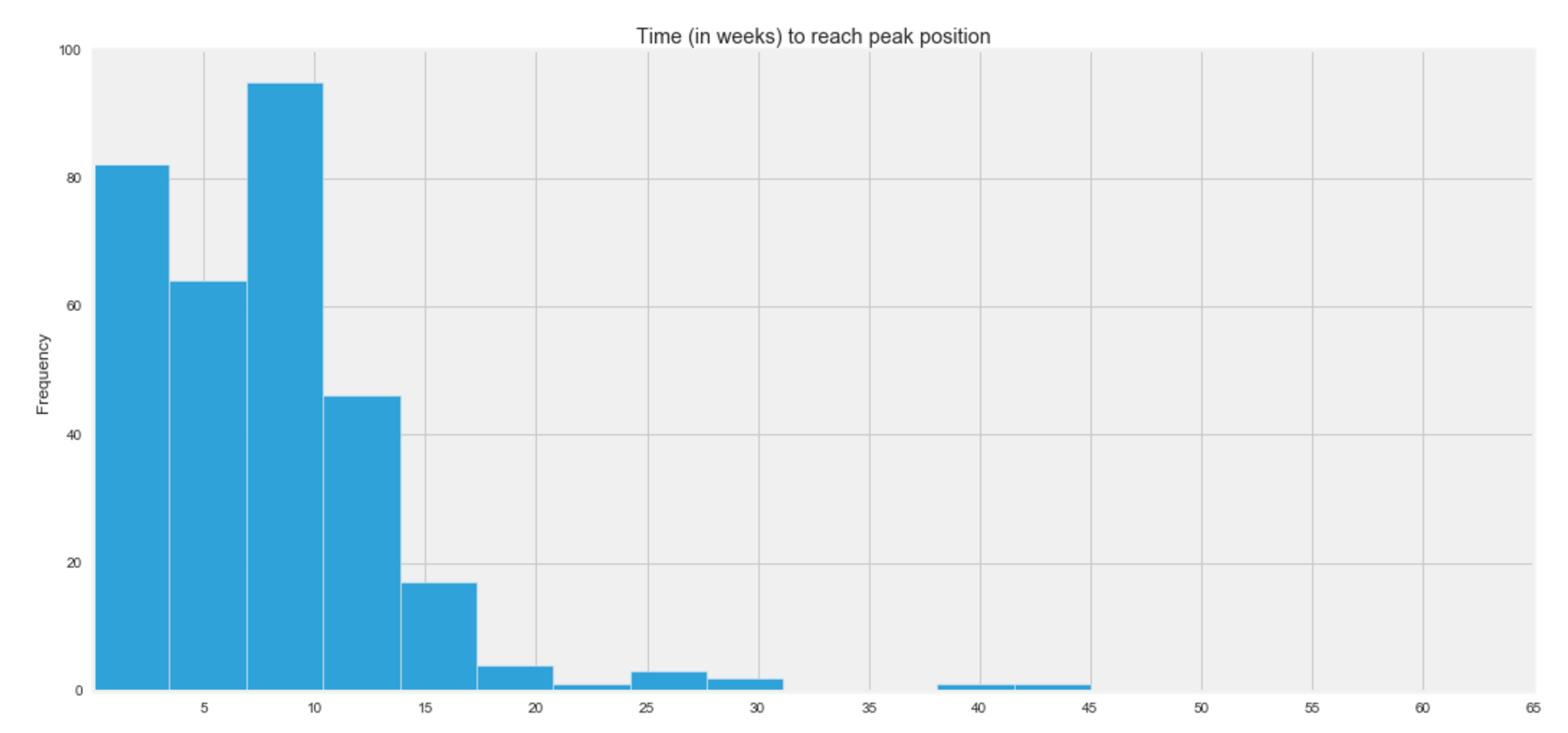
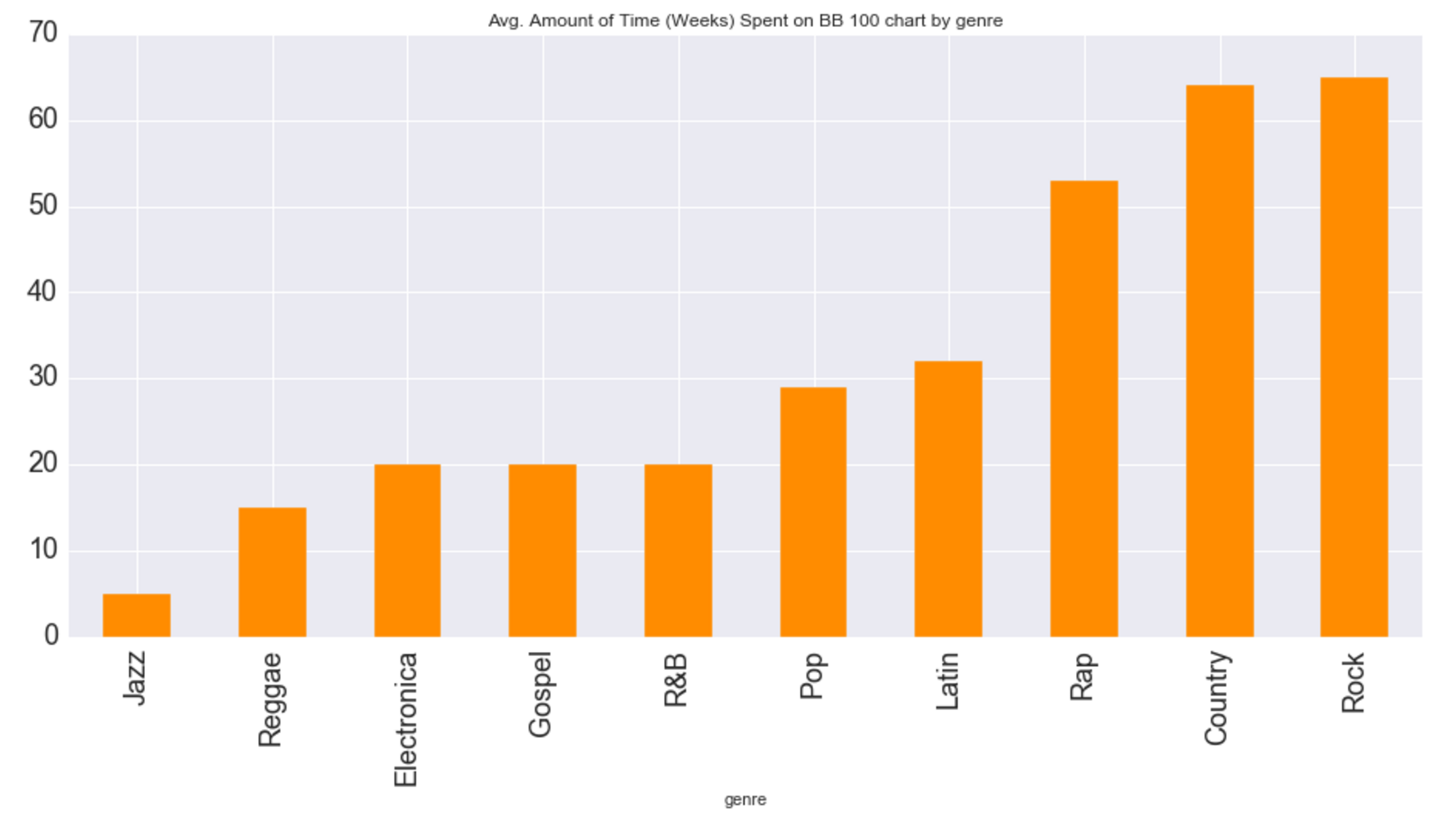
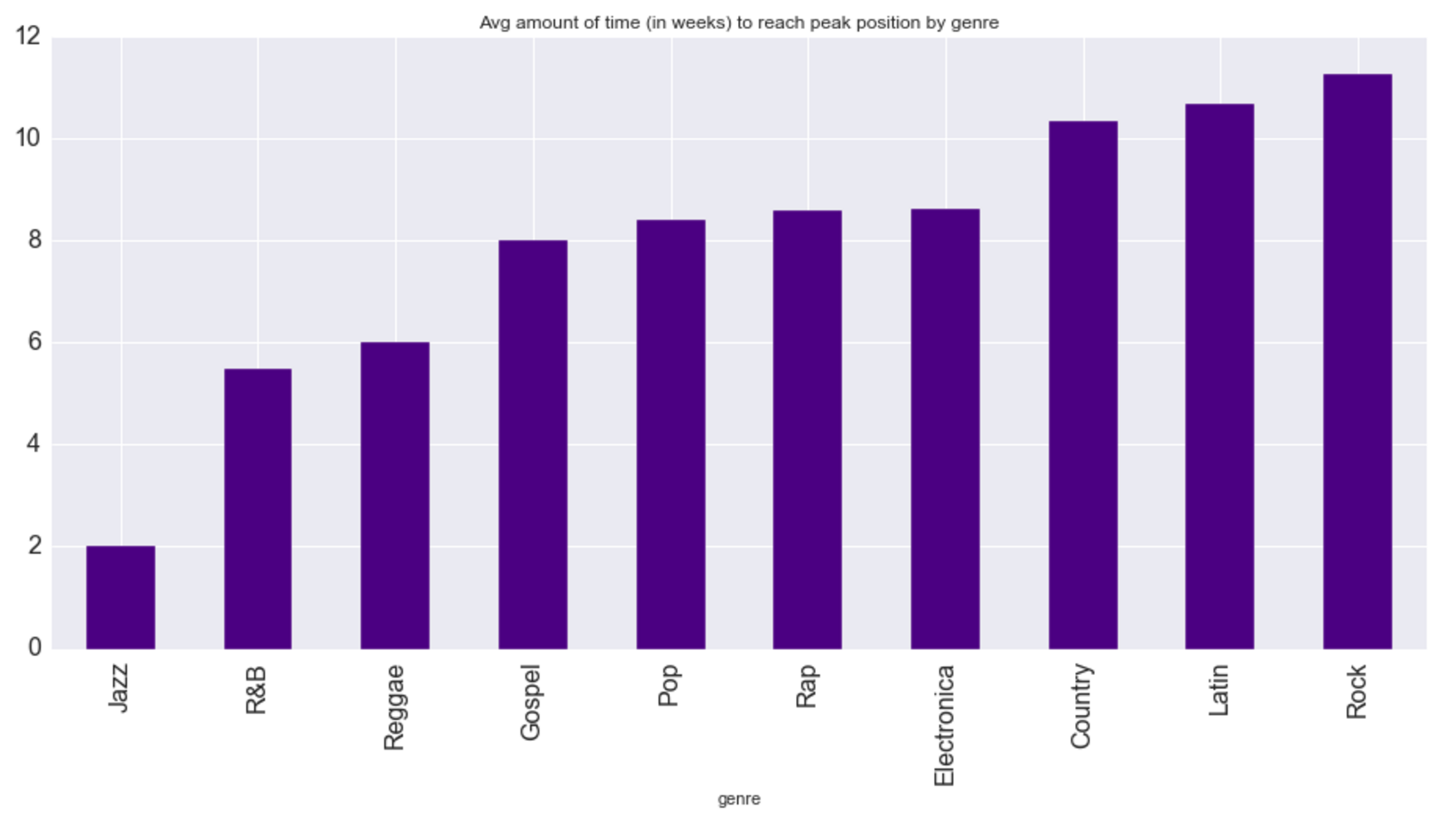
##STEP 4: Problem Statement
In exploring the questions of ‘what made a hit soar to the top of the charts?’ and ‘how long did a hit stay there?’, one first has to set definitons for what qualifies as a successful hit.
I am choosing 2 indicators for a successful hit, which will be the dependent variables of this study.
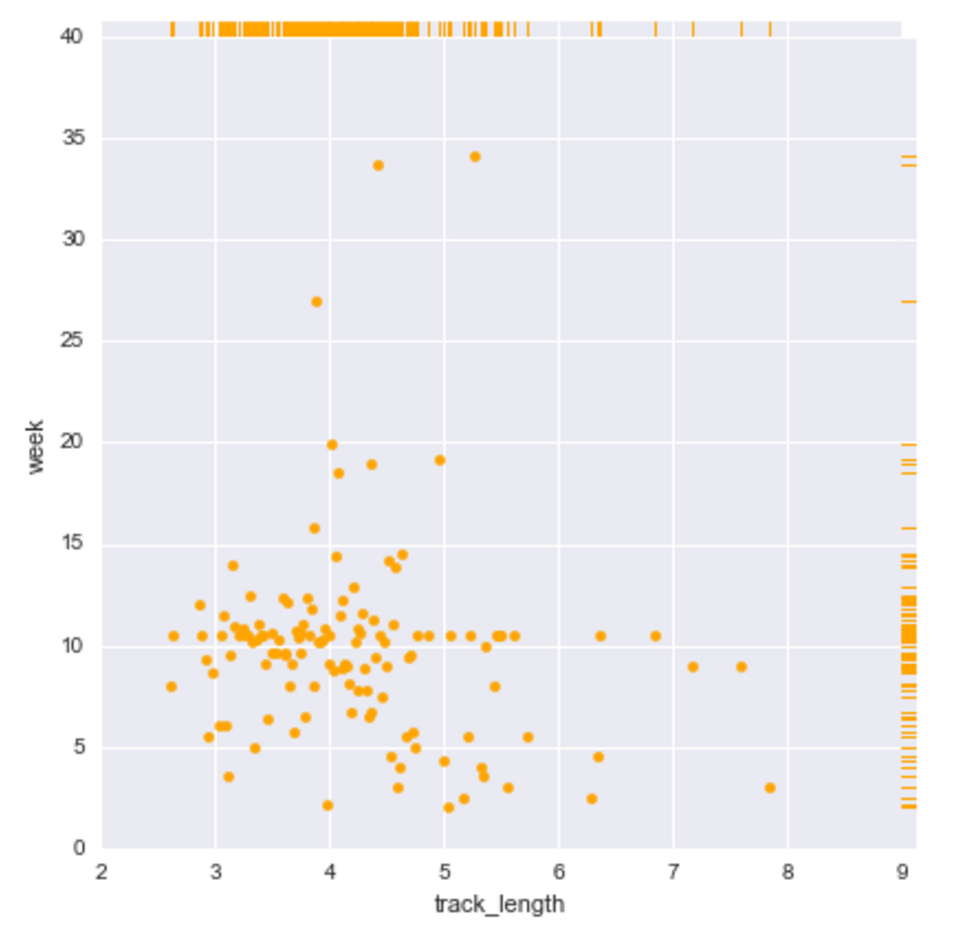
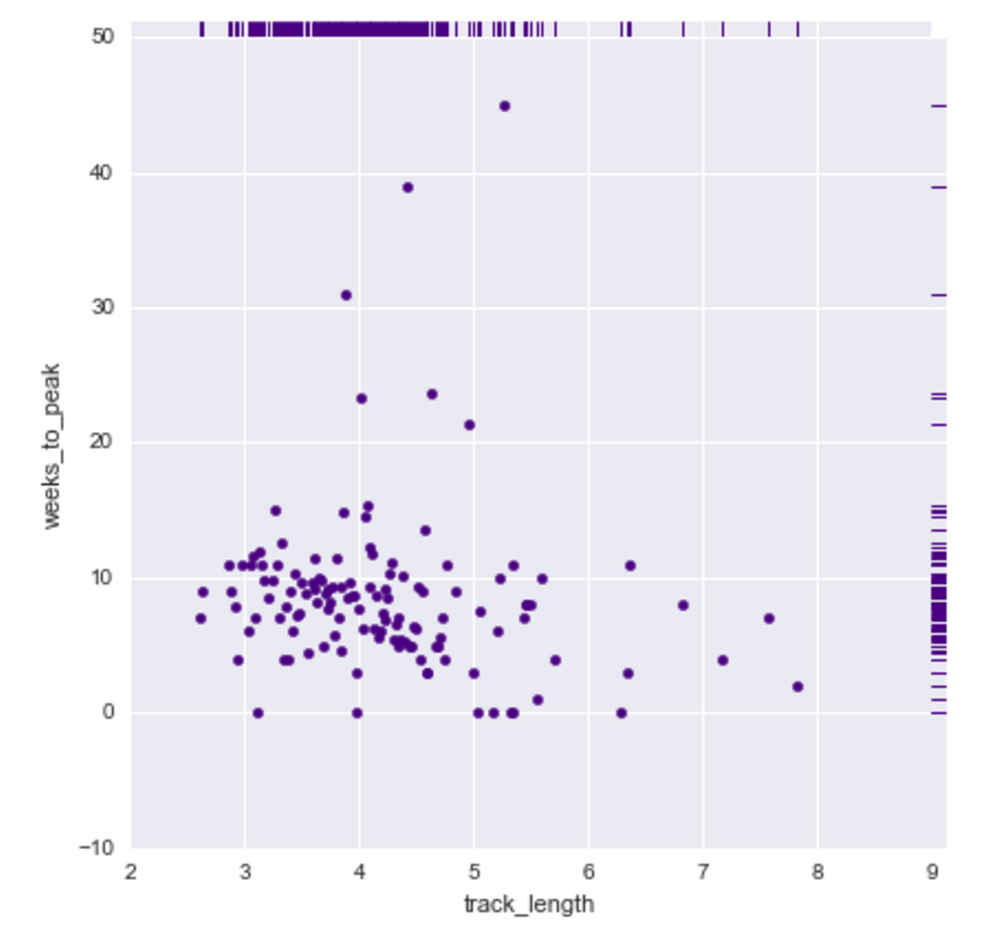
Y1 = Number of weeks a track was on the BB Hot 100 Chart for year 2000.
Y2 = Amount of weeks a track took to rise to its peak in year 2000.
A successful track will have a large Y1 and small Y2.
Problem Statement: Does the genre of a song or its length (in seconds) influence the success of a hit? By comparing genre of song with Y1 and Y2, and track length in seconds with Y1 and Y2, we may observe whether a correlation exists with the independent variables. If a correlation is observed, further investigation is warranted.
Null Hypothesis 1: The genre of a song does not impact the success of a hit on the BB Top 100 chart.
Null Hypothesis 2: The length of a song does not impact the success of a hit on the BB Top 100 chart.
Alternate Hypothesis 1: The genre of a song does impact the success of a hit on the BB Top 100 chart.
Alternate Hypothesis 2: The length of a song does impact the success of a hit on the BB Top 100 chart.
Sources support for Null Hypothesis: http://www.wired.com/2014/07/why-are-songs-on-the-radio-about-the-same-length/
Sources support for Alternate Hypothesis: http://www.motherjones.com/kevin-drum/2014/08/most-songs-are-three-minutes-long-because-thats-how-most-us-them
Assumptions of data:
1) Assuming normal distribution; I will be looking at averages.
2) Assuming no situation where two songs from two different artists have the same title
3) Genre is a proxy for artist. Although there were some questionable categorizations of artists into genres, I am assuming that genre popularity will serve as a representation of artist popularity (i.e., if artist is from rock genre, they are probably popular). I will not be looking at individual artist popularity.
Risks:
-Not enough variables being looked at. Only considering 2 metrics and 2 independent variables out of many possible factors. Also, the data analysis is not taking into account the underlying distributions.
-The way that songes are categorized into genres categorization affects the Y1 and Y2 measures. Furthermore, I combined two groups of genres in the data cleaning process, assuming they were the same (i.g., R & B was combined with R&B; and Rock combined with Rock’n’roll).
-When reviewing weeks to reach peak position for songs, there is a risk that 2 songs that did not change much in rank could be considered equally successful by this measure, regardless of how how high or low ranks were.
-Another risk is that a song can take a long time to rise to its peak, which is penalized in this measure Y2, even though it rises many ranks). To address this risk, future investigations should also consider the positive changes in rank (rise), the negative changes in rank (drop), and the overall change in rank.
Conclusions:
The genre of a song does impact the success of a hit on the BB Top 100 chart, according to the metrics I chose (Y1 and Y2).
The length of a song does not impact the success of a hit on the BB Top 100 chart, according to the metrics I chose (Y1 and Y2).
The real conclusion:
Need to include more variables in data analysis.
Need to justify assumptions or change assumptions based on evidence.
Need to go back and tidy up data further (specifically, genres section of data)
Future Steps_______________________
-2 tailed t-test for one-sample
-Model and see if it fits with data from future years