
APIs + Random Forests -- Exploring What Factors Contribute to Movie Ratings
Executive Summary
The aim of this report is to explore tree-based models that use data from IMDb.com to determine what movie attributes predict whether movie ratings will be high or low. The goal of this project is to collect data on the top and low movies of all time (as ranked on IMDb) and construct a tree-based model to understand what factors contribute to ratings. Data was scraped from IMDb.com (and Rotten Tomatoes, but was not used in analysis), cleaned and prepped for ensemble tree-based modeling. Models were then evaluated and tuned. The results indicate that length of a movie as well as number of Oscar wins and nominations were more significant factors than others. The recommended tree-based classifier is a Cross-validated Bagging Classifier model with the following parameters (found using Gridsearch):
{‘base_estimator__max_depth’: 5, ‘base_estimator__max_features’: None, ‘base_estimator__min_samples_leaf’: 3, ‘base_estimator__min_samples_split’: 5, ‘bootstrap_features’: False, ‘max_features’: 0.7, ‘max_samples’: 0.5, ‘n_estimators’: 10}
The report concludes that tree-based models are suitable to address the task of determining which movie attributes lead to certain ratings. In this analysis, the main factors were the length of the movie and the number of Oscar Wins and Nominations received. However, it is recommended that another, more comprehensive analysis include features that were excluded from this analysis (with appropriate preprocessing of data); and resulting models from such analysis should be tested on data of most popular movies (using the following to evaluate model performance: Confusion matrix, classification report, ROC curve/AUC).
Introduction
In a parallel universe, I was hired by Netflix to examine what factors lead to certain ratings for movies. My parallel self asked me to help out because she is need of a break. So, I agreed.
Given that Netflix does not currently store this type of data, I will acquire data from IMDb.com over top and low movies. In this post, I will demonstrate how tree-based models are useful in determining what movie attributes can predict whether a movie’s rating will be high or low. After performing EDA, I proceeded to construct several tree-based models and attempted to predict a corresponding ratings (high or low) for movies.
Methods
First I acquired data from IMDb.com by utilizing OMDB API and Beautiful Soup (a Python package for parsing HTML documents) to scrape the website for the top 250 and lowest 100 movies and their details (ratings, directors, year of release, etc.).
I recategorized some multi-class, categorical variables that had a large number of classes. I also transformed the target variable from a continuous variable (ratings from 0 to 10) to a categorical one (high/low indicator variable for IMDb Rating). Both forms of the target variable were used in the analysis.
The features explored as the factors that determine high/low ratings were as follows: production company, director, genre, language, MPAA rating, runtime, year, and number of Oscar Wins and Nominations.
I then built several tree-based models using several methods. Each model was evaluated based on it’s accuracy (or mean squared error for regressor models) score. See analysis plan below:
ANALYSIS PLAN (score metrics to use in evaluation of model are in parenthesis):
1) Cross-Validated, Decision Tree and Bagging Regressor with y1 as continuous variable (mean-square error)
2) Cross-Validated, Decision Tree and Bagging Classifier with y1 as categorical variable (accuracy)
3) Compare score metrics and choose better model
4) Cross-Validated Bagging model (Classifier) with some bucketed features
5) Compare score metrics and choose better model
6) Then, determine feature importance using random forest (Feature Ranks using their importance scores)
7) GridsearchCV Bagging model with only important features (Best parameters, best score)
8) Test model on new data: Most popular movies on IMDb (ratings range from 5.3 - 9.5) (Confusion matrix, classification report, ROC curve/AUC)
Results
Dataset of 350 movies with ratings.
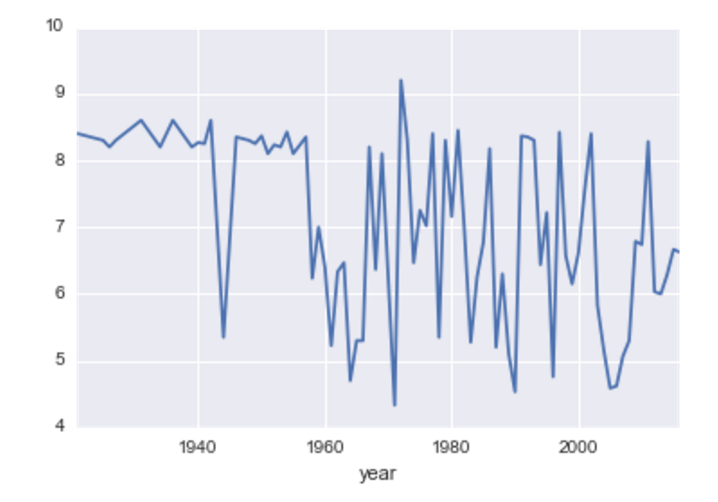
Average Ratings Over Time (Years):
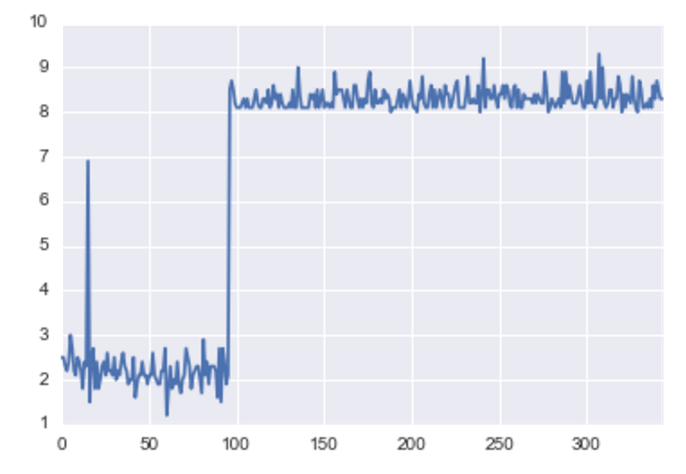
Ratings Distribution (as continuous variable):
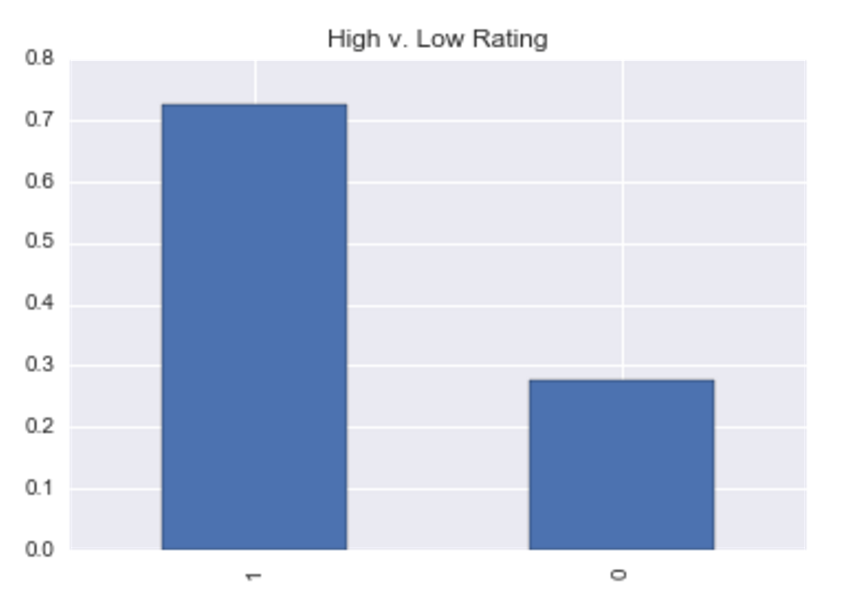
Ratings Distribution (as categorical variable; 1 = high, 0 = low):
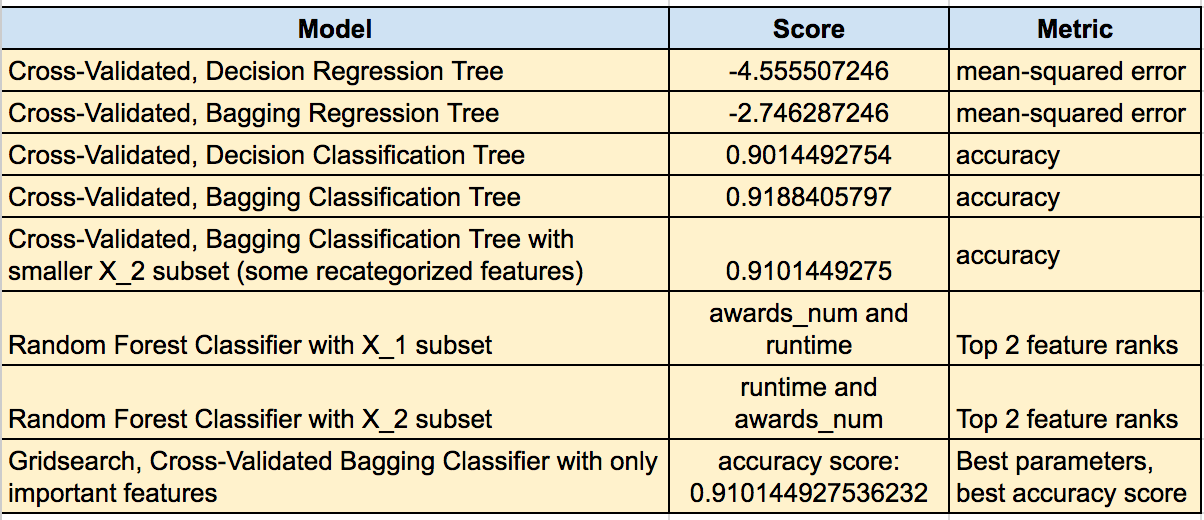
Model Evaluation:
Table 1: Tree-Based Models and their scores:
Using Random Forests to Determine Feature Importances:
Random Forest with X_1 feature subset:
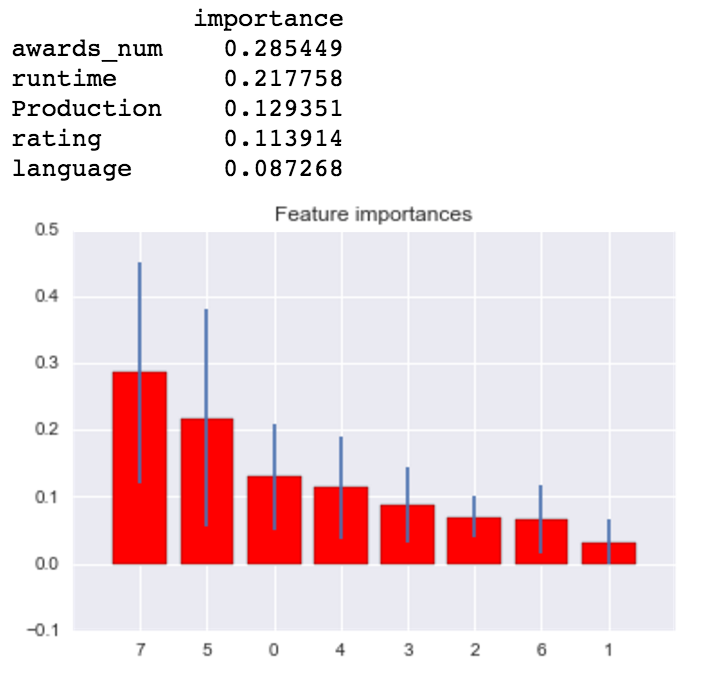
Random Forest with X_2 feature subset:
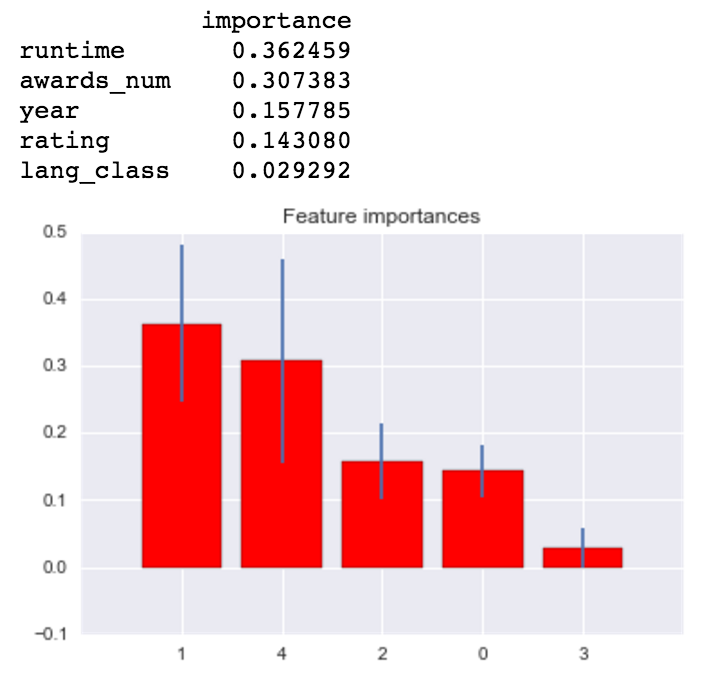
Gridsearched, Cross-Validated Bagging Classifier modeled with only two most important features:
Best Parameters:

Best Accuracy Score: 0.91014492753623188
Discussion / Interpretation of Results
The results indicate that length of a movie as well as number of Oscar wins and nominations were more significant factors than others. The recommended tree-based classifier is a Cross-validated Bagging Classifier model with the following parameters (found using Gridsearch):
{‘base_estimator__max_depth’: 5, ‘base_estimator__max_features’: None, ‘base_estimator__min_samples_leaf’: 3, ‘base_estimator__min_samples_split’: 5, ‘bootstrap_features’: False, ‘max_features’: 0.7, ‘max_samples’: 0.5, ‘n_estimators’: 10}
Although this model did not have the best accuracy score, it is most likely the most generalized model due to the gridsearch method. In order to test this hypothesis, model needs to be tested on a different dataset of movies rated on IMDb.com.
Conclusion
Tree-based models are suitable to address the task of determining which movie attributes lead to certain ratings. In this analysis, the main factors were the length of the movie and the number of Oscar Wins and Nominations received. However, in order to obtain a more accurate model, I need to go back and re-do analysis with other features that were excluded as well as re-categorized categorical variables. Only then can I attempt to build a powerful model and obtain meaningful results. The selected model would then need to be tested on a data set of the most popular movies and their ratings from IMDb.com.
Recommendations
It is recommended that another, more comprehensive analysis include features that were excluded from this analysis (with appropriate preprocessing of data); and resulting models from such analysis should be tested on data of most popular movies. The models should be evaluated by analyzing confusion matrices, classification reports, and ROC curves/AUC.
The next steps listed below are recommended:
• Recategorize multi-class categorical variables with many classes (50+) by region
• Build another model for y2 variable (TomatoMeter Rating)
• Test models on new data: Most popular movies on IMDb (ratings range from 5.3 - 9.5)
• Evaluate performance of model using the following: Confusion matrix, classification report, ROC curve/AUC